- Nexan Insights
- Posts
- From Data Chaos to ML Glory
From Data Chaos to ML Glory
Navigating the Maze of RAG, Fine-Tuning, and Tooling in ML Engineering
Ajit Banerjee
December 16, 2024


Imagine you've decided to make a superhuman—let's call it GenAI: it's going to be the ultimate know-it-all, capable of extracting wisdom from PDFs, websites, or whatever dusty old digital corner you throw at it. But building this machine is like preparing a meal for a royal banquet when the kitchen is a chaotic mess. There's data everywhere, and figuring out the right recipe for fine-tuning, feeding, or choosing the tools for this majestic ML feast is a real challenge.
Buckle in, because we're about to embark on a journey where machine learning engineering meets the reality of practical constraints, from dealing with GPUs that have opinions to tools that don’t always work as expected. Let’s explore the big hurdles and insights straight from an ML engineer who's seen it all—from the glitzy halls of Amazon to scrappy startup basements.
1. The Myth of the Perfect Tool - To Buy or To Build?
Every ML engineer has faced this existential question: should you buy the shiny new software tool that promises to solve all your data problems, or should you build something in-house that’s exactly (well, sort of) what you need? Spoiler alert: neither option is perfect.
Buying tools is like buying a new kitchen appliance—it looks amazing on the store shelf, but when you bring it home, you realize it needs you to rewire your entire kitchen to make it work. Building it in-house is like deciding to make a blender from scratch—you could do it, but are you sure you want to?
The ML engineer had to navigate this classic dilemma in multiple contexts—from highly secure defense projects to working at a major tech firm with procurement headaches. In one instance, the solution was using a JSON file as a makeshift vector database instead of a specialized, costly vector DB. Why? Because it was enough. It was faster, cheaper, and worked without reinventing the wheel.
Making the decision to buy or build ML tools can impact both operational efficiency and expenses. For example, a ML engineer at AWS that I spoke to once faced a dilemma: rather than investing in a costly vector database, they repurposed a JSON file to achieve similar results efficiently.
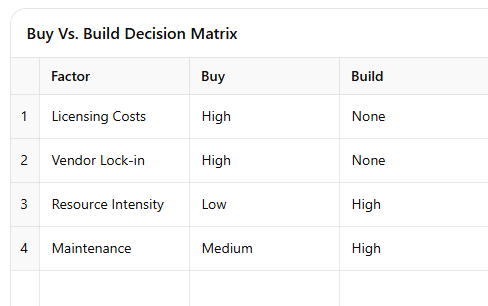
Table 1: Buy vs. Build Decision Matrix
The ML Engineer’s Dilemma: Buy or Build?
2. RAG Pipeline - Riding the Semantic Search Unicorn
RAG (Retrieval-Augmented Generation) pipelines are like the unicorns of ML: magical, powerful, and very temperamental. When you need your GenAI model to know something hyper-specific, RAG comes in to save the day, turning a clueless language model into a sharp, well-informed genius by feeding it the right context at the right time.
Our ML engineer's story featured RAG as a multi-layered tool for extracting relevant information. Imagine you’re trying to train your model to understand acronyms across different industries—RAG was used to pull the most relevant examples based on the query type. But the challenge was deciding how much was enough: should you fetch 5 examples or 30? Turns out, just like Goldilocks, the solution was to find what was just right by running endless tests.
RAG pipelines are invaluable for augmenting models with relevant context. For instance, an ML engineer used RAG to tailor responses by industry, enhancing model relevance. However, testing was essential to identify the optimal retrieval quantity for accuracy and cost-effectiveness.
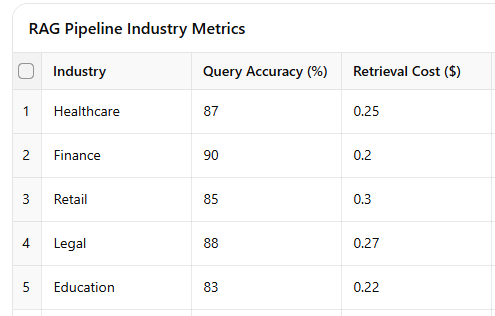
Table 2: RAG Pipeline Metrics Across Industries
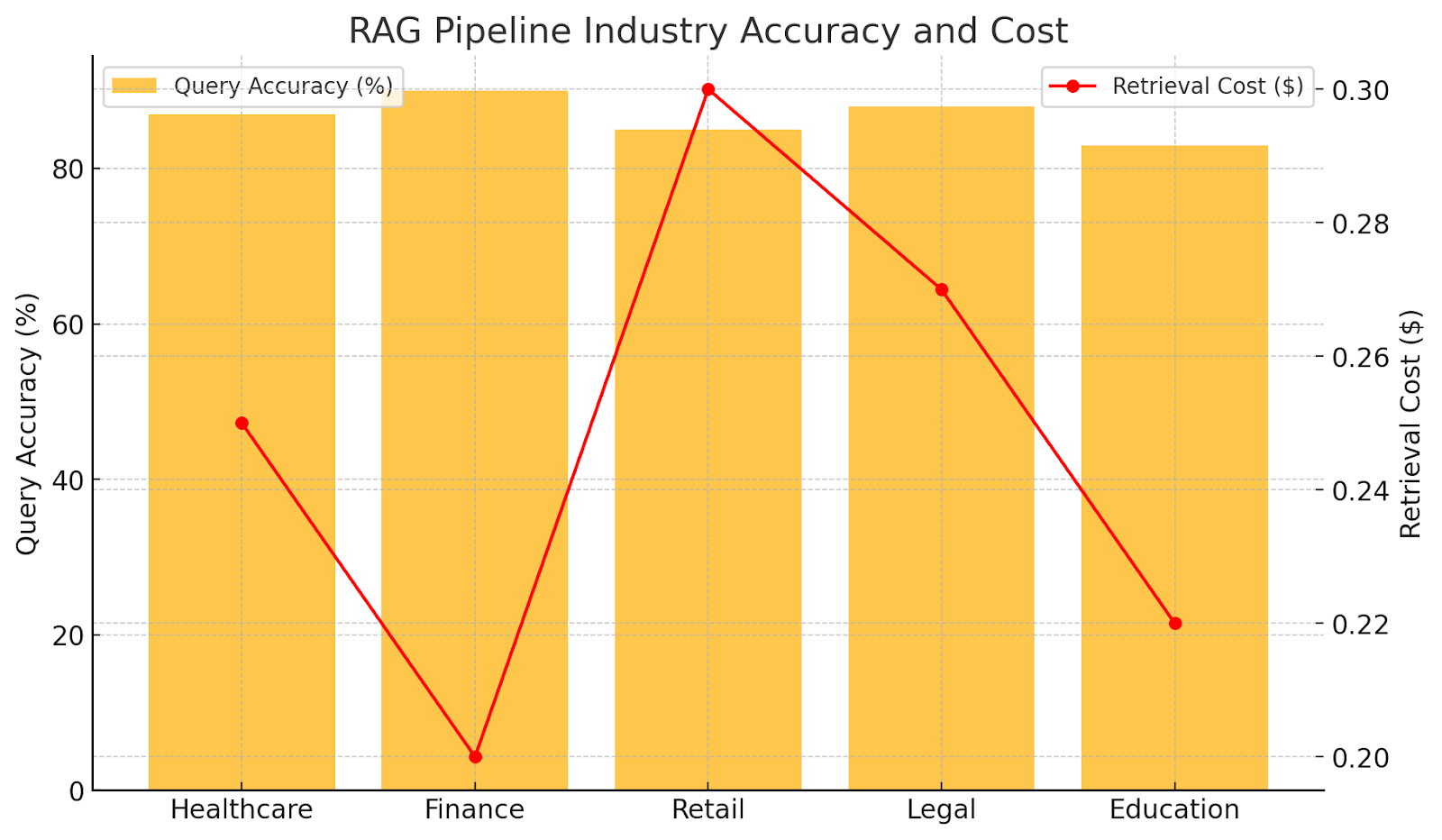
RAG Pipeline Industry Accuracy And Cost
Taming the RAG Unicorn: How Retrieval-Augmented Generation Works
3. Fine-Tuning vs. Instruct Tuning - The Cost-Efficiency Tango
Fine-tuning a model is like raising a well-behaved pet—you train it, give it a ton of examples, and expect it to behave predictably. But there’s an alternative: instruct tuning, which lets you teach a base model with specific instructions, making it more cost-effective.
The ML engineer that I spoke to, found this out the hard way. When security and cost were big concerns (let’s face it, fine-tuning is expensive!), instruct tuning was the go-to move. It allowed compressing knowledge efficiently—training a model on several hundred examples to teach it core competencies, without the high cost of specialized fine-tuning. This method was faster, cheaper, and surprisingly effective for less complex tasks.
Fine-tuning a model is ideal for complex applications, but instruct tuning offers a cost-effective approach for simpler needs. AWS engineers found instruct tuning invaluable for cost-sensitive applications that required less depth but maintained accuracy, effectively reducing model training expenses.
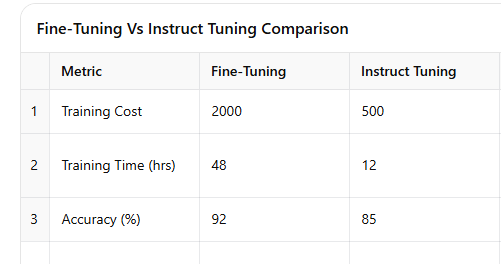
Table 3: Comparison Between Fine-Tuning and Instruct Tuning
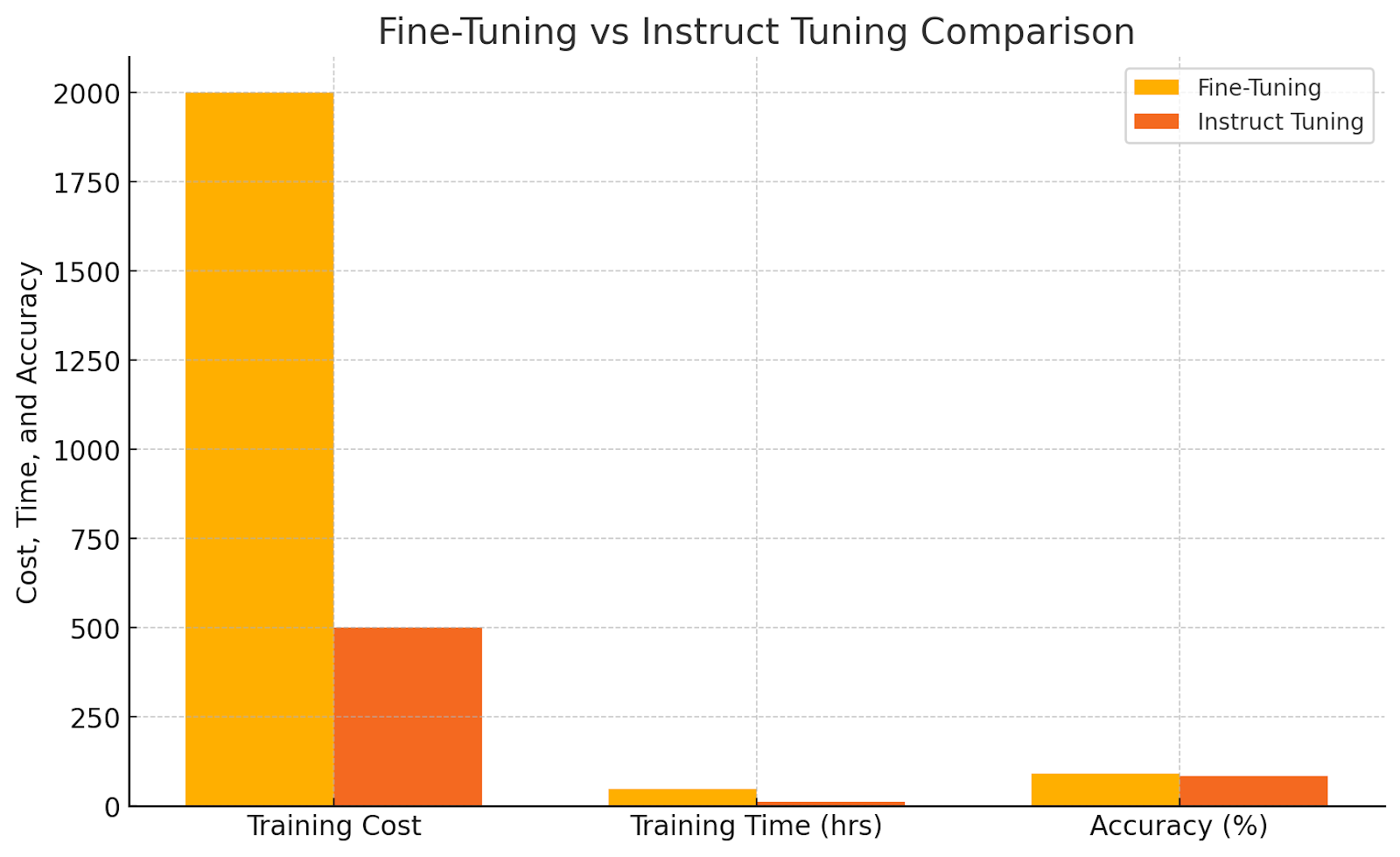
Fine Tuning VS Instruct Tuning Comparison
Fine-Tuning vs. Instruct Tuning: Training Methods Compared
4. GPU Utilization - The Great Balancing Act
Imagine you have an overqualified chef (a GPU) who only wants to do the most glamorous cooking tasks. When it comes to something mundane like chopping vegetables (basic data processing), the chef refuses and insists that’s beneath them.
In ML, GPUs are the chefs who prefer doing inference rather than the “housekeeping” tasks like data preparation. Our ML engineer shared how data-related workloads barely ever get GPUs involved—they’re simply not efficient for that. However, when it came to embedding generation for RAG, that’s when the GPU put on its chef hat and got involved. It’s about knowing when to call in the GPU cavalry.
In ML engineering, maximizing GPU efficiency is crucial. Engineers noted that GPUs were most effective for inference tasks rather than basic data processing. Optimizing GPU use for embeddings in RAG pipelines enabled rapid query responses without unnecessary cost.
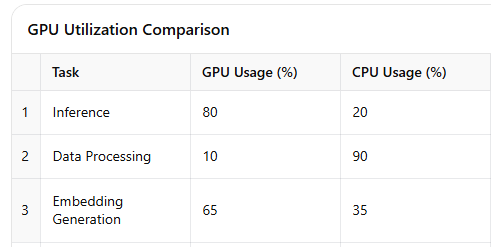
Table 4: GPU vs. CPU Utilization Across Tasks
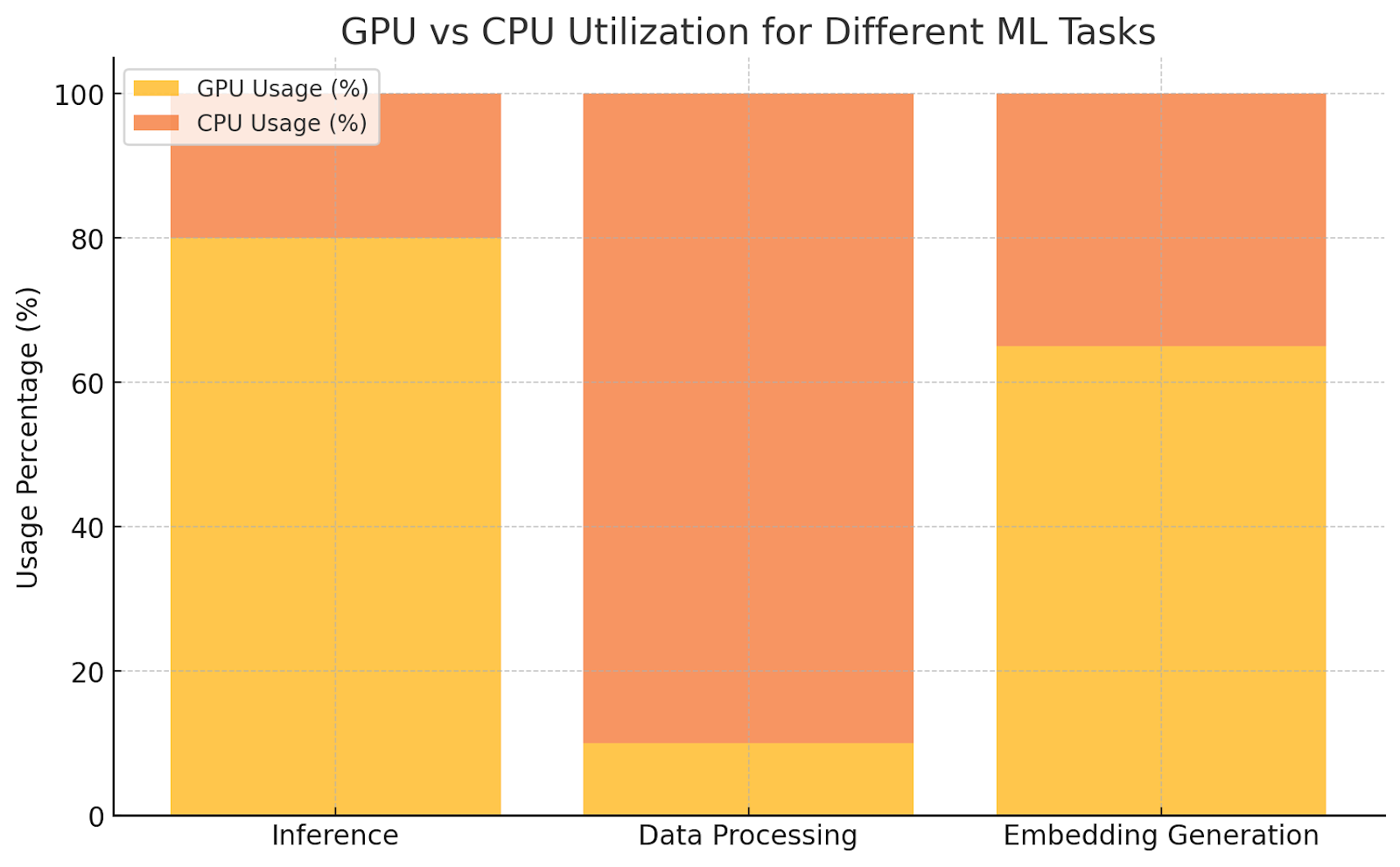
GPU vs CPU Utilization

GPU vs. CPU Utilization in Machine Learning Workloads
5. What the Tools Get Wrong - A Wishlist for ML Engineers
No tool is perfect, and the ML engineer I talked to was painfully aware of it. Imagine working with a system that refuses to tell you why it failed. This is often the case with LLMs: they are powerful, but when they mess up, they don’t give you much insight into why.
One big wish? Better understanding and evaluation tools that can easily tell you where models struggle—like some form of “hard example mining” that helps identify edge cases during model training. Current tools like Weights & Biases were useful for tracking experiments, but the ML world is still waiting for something that combines prompt evaluation, fine-tuning insights, and meaningful diagnostic tools in one package.
Current ML tools lack effective evaluation metrics and error diagnostics, especially for large language models (LLMs). Engineers express the need for robust hard example mining to refine model boundaries, particularly when scaling ML solutions across diverse applications.

Table 5: Comparison of Existing and Ideal Tool Features for ML Engineers

Table 6: ML Engineer's Wishlist for Tool Features
The ML Engineer’s Wishlist: The Quest for the Perfect Tool
Building a robust ML system isn’t just about having state-of-the-art models or fancy GPUs. It’s about navigating real-world constraints, making tough decisions on tooling, balancing costs, and using RAG or fine-tuning effectively. It’s about knowing when to call in your “overqualified chef” or settle for an easy JSON file approach because it’s just good enough.
Ultimately, ML engineering is equal parts creativity and compromise. It’s about being pragmatic, knowing when to build, when to buy, and—most importantly—how to do more with less. It’s a fascinating world of trade-offs, hacks, and genius-level problem-solving, and perhaps that's what makes it so rewarding.
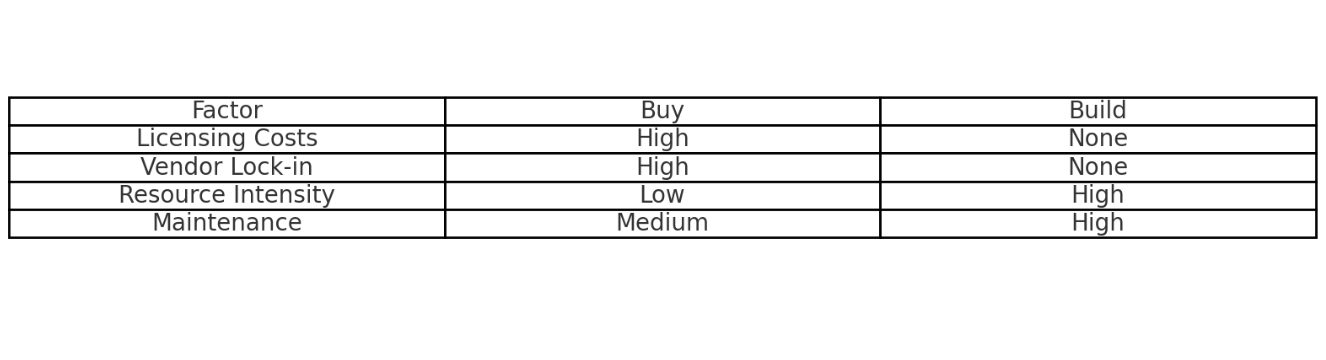
Table 7: Comparison of Buy vs. Build Decisions
The ML Engineer’s Journey: Navigating Challenges in Machine Learning Development
