- Nexan Insights
- Posts
- Optimizing Deep Learning Models
Optimizing Deep Learning Models
The Hardware, Software, and Everything In Between
Ajit Banerjee
April 21, 2025

This investor-focused table presents a structured comparison of key AI inference optimization strategies, highlighting the role of compilers, quantization, specialized hardware, and software innovations. The table covers Groq, Modular, NVIDIA, and other AI hardware and software players, offering insights into performance, efficiency, and market impact.

As AI model sizes grow and deployment targets diversify, the optimization of inference—how models are executed after training—has become a critical engineering challenge. From compiler frameworks to low-bit quantization and kernel-level tuning, a new breed of startups (Modular, Groq) and incumbents (NVIDIA) are redefining the efficiency boundaries of AI systems. This analysis examines the interplay between software and silicon, and how strategic trade-offs across memory, power, and compute are being navigated to deliver cost-effective, high-performance AI inference at scale.
1. AI Compilers: Translating Graphs into Hardware-Optimized Execution
Conceptual Shift:
Deep learning models are represented as computational graphs—networks of matrix multiplications, activations, and data transformations. Compilers transform these graphs into low-level code tailored for specific hardware architectures.
Key Players & Tools:
Modular: Compiler stack supports general-purpose hardware (CPU/GPU/TPU) and integrates with their language Mojo.
Groq: Custom compiler tightly tuned to their Tensor Streaming Processors (TSPs).
TVM/OpenXLA: Open-source options, but less performant at runtime due to generality.
Strategic Impact:
Reduces developer burden in writing hand-tuned code for every platform.
Enables multi-target deployment from a single model source.
Drives 20–30% improvement in latency and throughput over unoptimized frameworks.
Framework Support:
Framework | Compiler Support | Target Hardware |
|---|---|---|
PyTorch | TorchScript, TVM | GPU, CPU |
TensorFlow | XLA | TPU, GPU |
Mojo/MAX | Modular Compiler | CPU, GPU, Groq |

Illustration of AI inference optimization, showing the role of compilers, GPUs, TPUs, and specialized processors in accelerating deep learning models.
2. Quantization: Compressing Models Without Losing Performance
Technical Background:
Quantization reduces the number of bits used to represent weights and activations (e.g., from FP32 to INT8), resulting in:
Smaller memory footprint
Higher compute efficiency
Faster execution
Performance Trade-off:
Properly tuned quantized models retain ~98% of original accuracy while requiring up to 4× less memory bandwidth and storage.
Strategic Implication:
Enables deployment of LLMs and vision models on resource-constrained edge devices.
Facilitates multi-instance model hosting on shared infrastructure (e.g., LLM serving with A100 or L40s).
Example:
Model | Precision | Memory Use | Inference Latency |
|---|---|---|---|
LLaMA 7B | FP32 | ~28GB | 110ms |
LLaMA 7B | INT8 | ~7GB | 45ms |
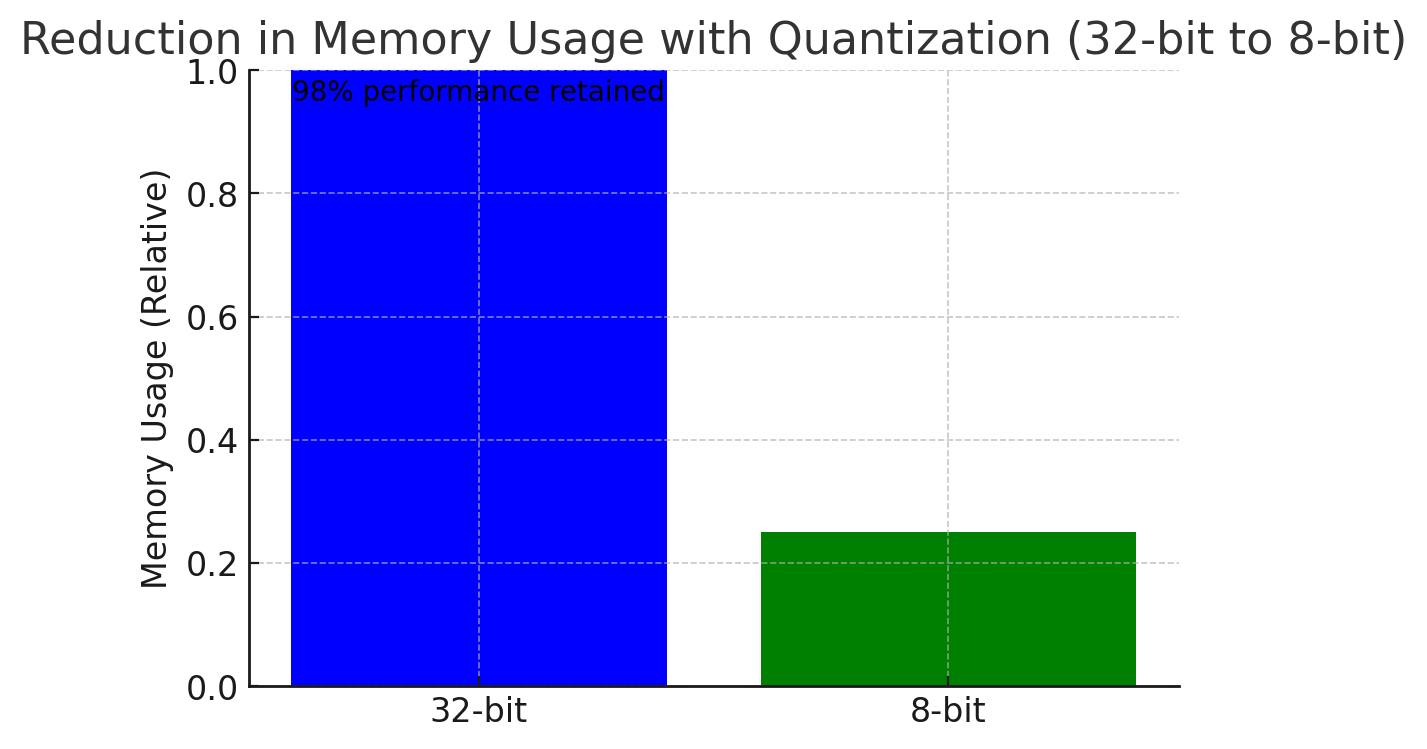
Quantization reduces memory usage from 32-bit to 8-bit while retaining 98% performance.
3. Hardware Evolution: Groq's LPUs and the Architecture Trade-off
Background:
Groq’s architecture started with TSPs optimized for vision models. As LLMs became dominant, Groq scaled up by clustering TSPs into LPUs (Language Processing Units).
Trade-off Landscape:
Pros: Linear performance scaling by parallelizing across chips.
Cons: Memory fragmentation, inefficient utilization, increased interconnect latency.
Efficiency Challenge:
LPUs are not memory-optimized. Bridging the gap between compute throughput and memory bandwidth remains Groq's core challenge for large model inference.
Strategic Positioning:
Best suited for high-throughput batch inference.
Sub-optimal for models with high memory-to-FLOP requirements (e.g., LLMs >70B).

Illustration of Groq’s TSP architecture, showing increased power but raising efficiency concerns in handling large AI models.
4. MAX and Mojo: Modular's Unified Inference Stack
MAX (Modular Accelerated eXecution):
Includes compiler, kernel library, and deployment runtime.
Targets CPUs and GPUs with minimal developer friction.
Mojo Language:
Combines Python syntax with C++ performance.
Exposes fine-grained control for kernel developers without sacrificing readability.
Key Innovation:
Human-written kernels in Mojo outperformed NVIDIA’s cuBLAS/cuDNN implementations by up to 20% in Modular’s internal benchmarks—especially in custom ops for computer vision and transformer workloads.
Implication for Developers:
Faster iteration with production-level performance.
Consolidated toolchain from development to deployment.

Groq’s TSP architecture stacks more power but raises efficiency concerns in AI model processing.
5. Inference Optimization: Compilers as the New Silicon
Distinction from Training:
Training: Requires large memory to store intermediate activations, emphasizes throughput.
Inference: Prioritizes latency and energy efficiency.
Compiler Role:
Applies static graph optimizations (e.g., op fusion, memory reuse).
Enables device-aware scheduling and kernel tuning.
Strategic Benefit:
Compilers act as force multipliers—improving performance without new hardware.
Hardware-neutral inference pathways mitigate vendor lock-in.
Groq Insight:
Compiler-driven execution allowed Groq to adapt its vision-focused chips for transformer workloads without hardware redesign—underscoring compiler leverage as a substitute for silicon agility.
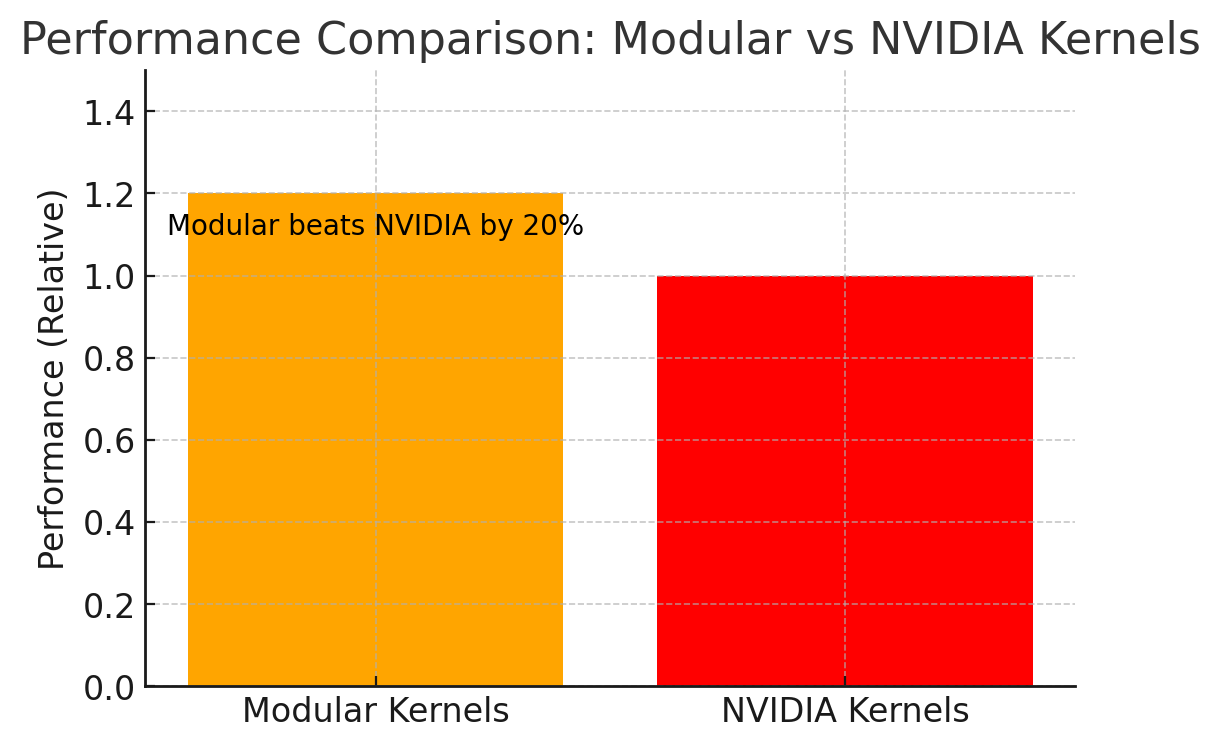
Modular kernels outperform NVIDIA kernels by 20% in relative performance.
6. Optimization as a Multi-Dimensional Trade Space
Key Trade-offs:
Speed vs. Accuracy (e.g., quantization)
Cost vs. Memory (e.g., GPU utilization vs. edge deployment)
Power vs. Compute (e.g., mobile inference vs. server farms)
Multi-Axis Design Constraints:
Constraint | Levers | Optimization Target |
|---|---|---|
Memory | Quantization, weight sharing | Model size, loading time |
Power | Kernel tuning, sparsity | Edge deployments, mobile apps |
Latency | Op fusion, compiler scheduling | Real-time inference |
Cost | Model distillation, batching | Hosting efficiency |
Competitive Insight:
Modular and Groq are converging on the same problem: reducing TCO per inference without sacrificing flexibility. While NVIDIA relies on hardware-software integration, these startups lean heavily on compiler innovation and human-tuned kernels.

Comparing AI model training (learning tricks) to inference (performing them).
Takeaways for Operators & Investors
For Operators:
Compiler-first approaches provide flexibility and cost savings—especially for deployment across mixed hardware fleets.
Quantization and kernel tuning are low-hanging optimizations for most production models.
Toolchains like MAX offer unified pipelines, simplifying dev-to-prod transitions for inference workloads.
For Investors:
Moats shift to software layers. As hardware saturates, compiler and inference stack IP becomes the differentiation layer.
Groq’s challenge lies in scaling memory-optimized compute without architectural redesign.
Modular’s bet on developer productivity via Mojo and MAX can translate into faster adoption, especially in non-cloud-native enterprises.
3D comparison of AI hardware optimization across memory, speed, and cost for Groq, Modular, and NVIDIA.
Wrap Up: A Constant Race to Optimize
The deep learning world is evolving at breakneck speed, and the key players are in a constant race to build better, faster, and more adaptable solutions. Whether it's through specialized hardware like Groq's LPUs, software optimizations in MAX, or efficient coding practices with Mojo, the goal is clear—make AI cheaper, faster, and more scalable. But it’s a complex puzzle, with new pieces being added every day. If you’re an investor, the companies that will win this race are the ones that can adapt—not just to today’s challenges but to tomorrow’s unknowns.

AI hardware competition depicted as a race, with Groq emphasizing flexible performance and compilers against specialized hardware rivals.
