- Nexan Insights
- Posts
- The GPU Playground

This investor-focused table presents a structured analysis of NVIDIA’s dominant GPU ecosystem, driven by its CUDA software stack, high-performance libraries, and extensive developer adoption. It highlights key comparisons between NVIDIA and competitors, emphasizing the strategic advantages of CUDA, PyTorch, and parallel computing in AI workloads.

NVIDIA’s competitive edge in AI hardware is not derived from GPUs alone, but from its deeply integrated software ecosystem—centered around CUDA. This stack of developer tools, optimized libraries, and runtime environments creates a defensible advantage across both training and inference. As competitors struggle to build comparable alternatives, NVIDIA continues to set the pace in parallel computing, deep learning, and high-performance computing (HPC). This analysis dissects the underlying structures of NVIDIA’s advantage, and explores why its position remains durable in the face of accelerating AI workloads and fragmented industry standards.
1. CUDA: A Software Moat Around Hardware Innovation
The CUDA Platform Stack
CUDA (Compute Unified Device Architecture) is not simply a compiler or driver—it's an integrated platform comprising:
A runtime API and low-level driver model
Optimized libraries such as cuDNN (neural networks), CUTLASS (linear algebra), NCCL (multi-GPU communication)
Kernel abstractions for scheduling and parallelization
This deep software stack abstracts GPU hardware complexity and exposes consistent, high-level interfaces to developers.
Strategic Advantage:
Reduces engineering cost for ML practitioners via high-level APIs.
Enables performance portability across GPU generations.
Creates lock-in: once optimized for CUDA, switching costs to other frameworks rise sharply.
Competitive Context:
CUDA adoption began in earnest in the early 2010s.
Today, over 3 million developers use CUDA-enabled libraries.
Over 800 AI frameworks and applications rely on CUDA acceleration.

CUDA: The powerful glue binding APIs, computing platforms, and libraries to fuel GPU acceleration.
2. Developer Gravity: PyTorch and the CUDA Pipeline
Framework Integration & Abstraction
While CUDA is the backend engine, most developers interact through front-end frameworks like PyTorch. PyTorch abstracts CUDA via torch.cuda, allowing GPU utilization without explicit kernel code.
Industry Adoption:
PyTorch holds >60% share among AI researchers and ML engineers in major benchmark repositories (e.g., Papers With Code, HuggingFace).
NVIDIA collaborates directly with framework maintainers to ensure CUDA support for the latest ops and layers.
Ecosystem Feedback Loop:
Developers build models in PyTorch → CUDA runs under the hood
CUDA improves ops-level optimization → PyTorch performance increases
Faster training/inference → More adoption → More CUDA lock-in
Result: CUDA’s dominance is now reflexive—it improves as more developers use it, and more developers use it because it improves.
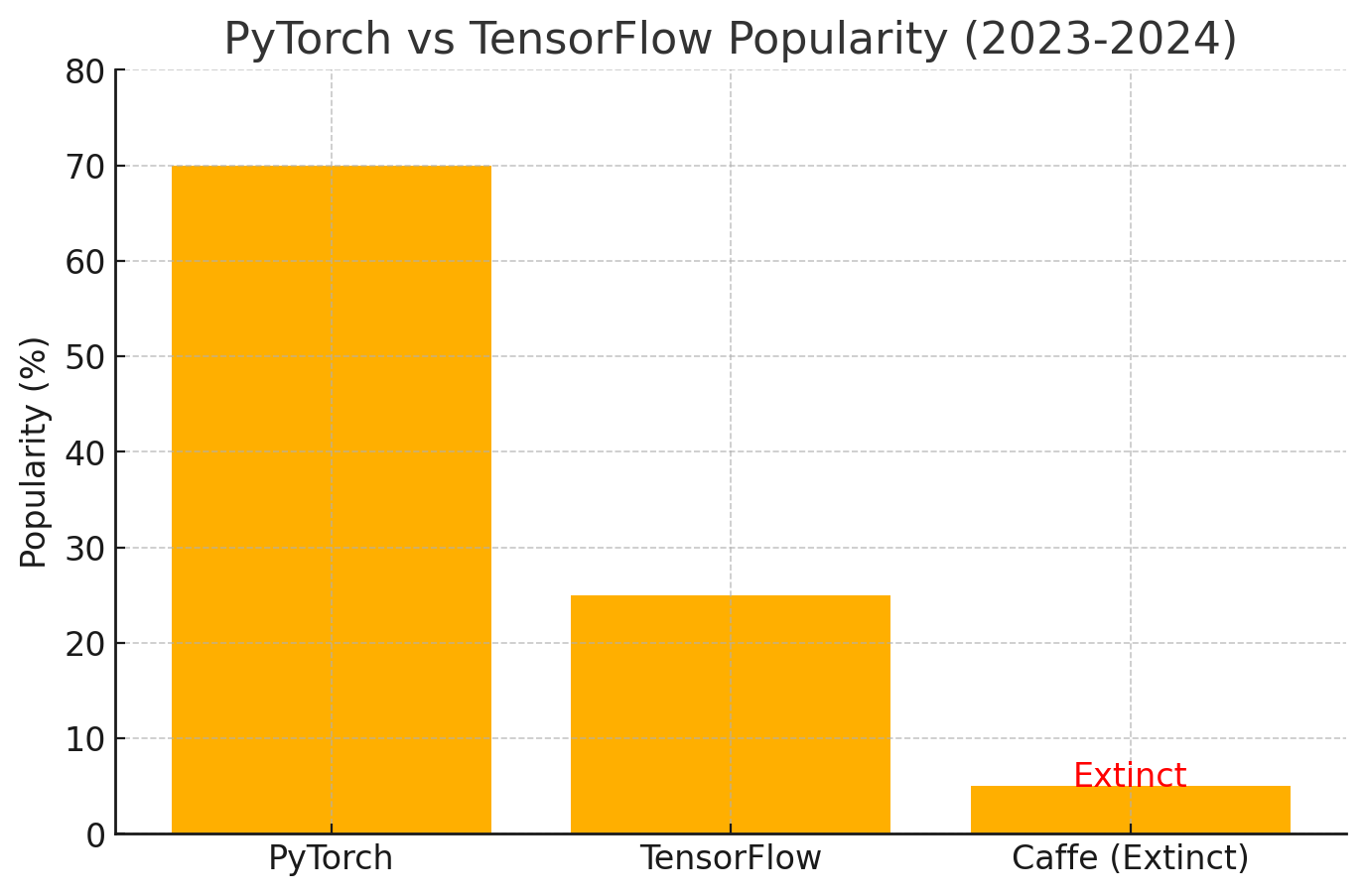
PyTorch dominates deep learning frameworks, while TensorFlow lags behind and Caffe fades into extinction.
3. Competing Runtimes: Fragmentation and Gaps
ONNX, oneDNN, and ROCm
NVIDIA’s closest software rivals include:
Intel’s oneDNN: Optimized for CPUs, limited GPU performance
AMD’s ROCm: Slower ecosystem uptake, limited by hardware support and fewer AI-specific libraries
ONNX Runtime: Interoperable, but lacks deep extensibility or backend tuning
Strategic Weaknesses of Alternatives:
Inferior kernel scheduling
Poor extensibility for novel architectures
Delayed or partial support for emerging models (e.g., diffusion models, LLM fine-tuning)
Industry Viewpoint:
ONNX is seen as a lagging indicator—reactive to community trends, not driving them. CUDA, conversely, is often ahead of the curve, adding kernel support and primitives before models reach mass adoption.

CUDA's toybox overflows with cutting-edge tools, while competitors struggle with outdated models and limited options.
4. AI Workloads: Diverging Demands of Training and Inference
Training: High Throughput, High Memory
Requires retention of intermediate activations
Involves gradient computation during backward pass
Memory-bound and throughput-limited
Inference: Low Latency, Lower Power
Focused on fast forward-pass execution
Emphasizes energy efficiency, especially in edge deployments
Optimized for batch sizes = 1 in real-time applications
CUDA’s Role:
Dynamic kernel fusion and operator-level optimizations adapt for both modes
cuDNN and TensorRT allow reconfiguration of workloads across training and inference
Strategic Insight:
The same GPU hardware—via CUDA tuning—can be efficiently repurposed across the model lifecycle, reducing TCO for hyperscalers and cloud providers.
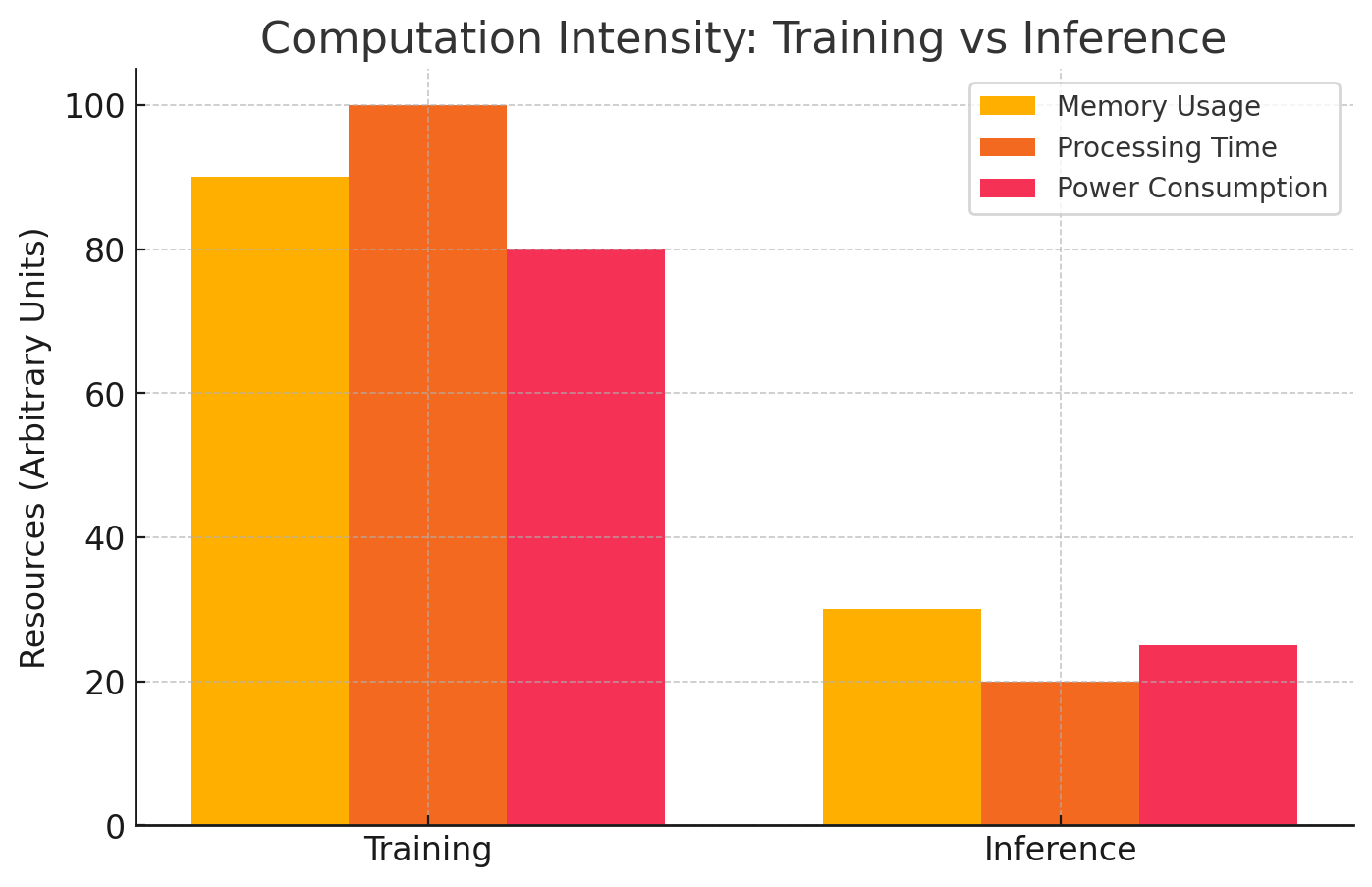
Training deep learning models demands significantly more memory, processing time, and power than inference.
5. Parallelism and Architecture-Level Superiority
GPUs vs CPUs in Parallel Tasks
CPUs are optimized for sequential, latency-sensitive tasks (high IPC, low thread count).
GPUs, particularly NVIDIA’s H100 and A100, are optimized for parallel workloads (thousands of cores, high memory bandwidth).
Example Benchmark (inference throughput):
Model Type | CPU (Intel Xeon 8280) | GPU (NVIDIA A100) |
|---|---|---|
BERT-Large | ~3 inferences/sec | ~750 inferences/sec |
ResNet-50 | ~250 inferences/sec | ~11,000 inferences/sec |
CUDA-Specific Enhancements:
Warp-level primitives enable fine-grained control
Tensor cores deliver 4x–10x speedups in mixed-precision matrix operations
Automatic mixed precision (AMP) reduces memory and compute without retraining

GPUs enable massive parallelism, cooking up computations faster than CPUs can handle sequential tasks.
Takeaways for Operators & Investors
For Operators:
CUDA is a moat, not middleware. Teams building on PyTorch or TensorFlow already depend on CUDA—even if they never touch the API directly.
Hardware alone is insufficient. Competing GPU vendors must replicate NVIDIA’s decade-long software investment to close the gap.
Optimizing for inference ≠ optimizing for training. Understand your deployment stack to avoid under-utilization.
For Investors:
Switching costs are sticky. CUDA's pervasiveness in tooling and training pipelines creates vendor lock-in well beyond the silicon layer.
Software leverage boosts margins. NVIDIA earns gross margins of 75–80% on AI GPU products, fueled by CUDA ecosystem premiums.
Beware false parity claims. Competitors may match FLOPs, but fail to replicate software performance, causing real-world deployment gaps.
Conclusion:
NVIDIA's leadership in AI and GPU acceleration is fundamentally software-defined. CUDA is more than a programming tool—it's an industrial strategy that synchronizes hardware, frameworks, and developer experience. As competitors pursue silicon parity, they still lag in the invisible layer that matters most: the code powering the stack. For now, NVIDIA remains the unchallenged orchestrator of the GPU playground.
